Structured data is a standardized format for providing information about a page and classifying its content. Search engines use structured data to understand the entities, attributes, and relationships that exist within a document — knowledge that plain HTML alone cannot communicate. Schema.org supplies the shared vocabulary; JSON-LD supplies the syntax; rich snippets supply the visible reward in the SERP.
What Is Structured Data in SEO?
Structured data is machine-readable markup added to a web page that explicitly labels content for search engine parsers. It converts implicit meaning — a price, an author name, a review rating — into an explicit, queryable fact that a knowledge graph can store and reuse.
Google, Bing, and Yahoo co-founded Schema.org in 2011 to unify this vocabulary across search engines.

Without structured data, a Googlebot crawler reads raw HTML and infers meaning through statistical patterns. With structured data, the crawler reads a declared fact: "@type": "Product", "price": "49.99". The difference is the shift from statistical probability to declared certainty a core principle in semantic SEO and entity-based ranking systems.
Structured data operates across 3 primary formats:
- JSON-LD — JavaScript Object Notation for Linked Data; Google’s recommended format.
- Microdata — HTML attributes embedded inline within page content.
- RDFa — Resource Description Framework in Attributes; used in academic and government contexts.
Schema.org: The Universal Vocabulary for Structured Data
Schema.org is an open, collaborative community project that defines a hierarchical vocabulary of Types and Properties. Every Schema.org Type represents a real-world entity: Person, Organization, Product, Article, LocalBusiness. Every Property describes an attribute of that entity: name, address, datePublished, aggregateRating.

The Schema.org vocabulary currently contains over 800 Types and 1,400 Properties. This hierarchy follows an inheritance model: LocalBusiness inherits all Properties of Organization, which inherits all Properties of Thing. Choosing the most specific Type available maximizes the semantic signal delivered to the search engine.
Google does not support every Schema.org Type for rich results. Google’s Search Gallery documents the 35+ supported rich result types, including FAQPage, HowTo, Recipe, Event, JobPosting, and Product. Implementing unsupported Types still improves entity understanding even without a rich result reward.
JSON-LD: The Recommended Format for Schema Markup
JSON-LD (JavaScript Object Notation for Linked Data) is a W3C standard that encodes linked data in a <script type="application/ld+json"> block placed in the <head> or <body> of a page. Google recommends JSON-LD over Microdata and RDFa because it decouples the markup from the visual HTML, making it easier to maintain, validate, and inject dynamically.

A complete JSON-LD block for an Article entity follows this structure:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Structured Data & Schema.org: The Complete SEO Guide",
"author": {
"@type": "Person",
"name": "CodeSolTech Editorial Team"
},
"publisher": {
"@type": "Organization",
"name": "CodeSolTech",
"logo": {
"@type": "ImageObject",
"url": "https://codesoltech.com/logo.png"
}
},
"datePublished": "2025-07-10",
"dateModified": "2025-07-10"
}
</script>The @context property declares the vocabulary namespace (https://schema.org). The @type The property declares the entity class. Every nested object with its own @type creates a sub-entity, forming a linked-data graph that search engines traverse to build entity profiles.
Dynamic websites inject JSON-LD programmatically via server-side rendering or CMS plugins, ensuring markup stays synchronized with page content.
Rich Snippets: The Direct Output of Structured Data
Rich snippets are enhanced SERP listings that display additional information star ratings, prices, availability, event dates extracted directly from structured data markup. Google processes the declared schema, validates it against its guidelines, and renders the extra SERP features for qualifying pages.

Rich snippets increase click-through rate (CTR) by 20–30% on average, according to data published by Backlinko’s CTR analysis.
Rich snippets differ from rich results and SERP features in scope:
- Rich Snippets — Enhanced baseline listings (star ratings, author, date).
- Rich Results — Distinct, visually separated SERP formats (carousels, panels).
- Knowledge Panels — Entity profiles pulled from the Google Knowledge Graph.
- Featured Snippets — Algorithmically selected answer boxes; schema-assisted but not schema-dependent.
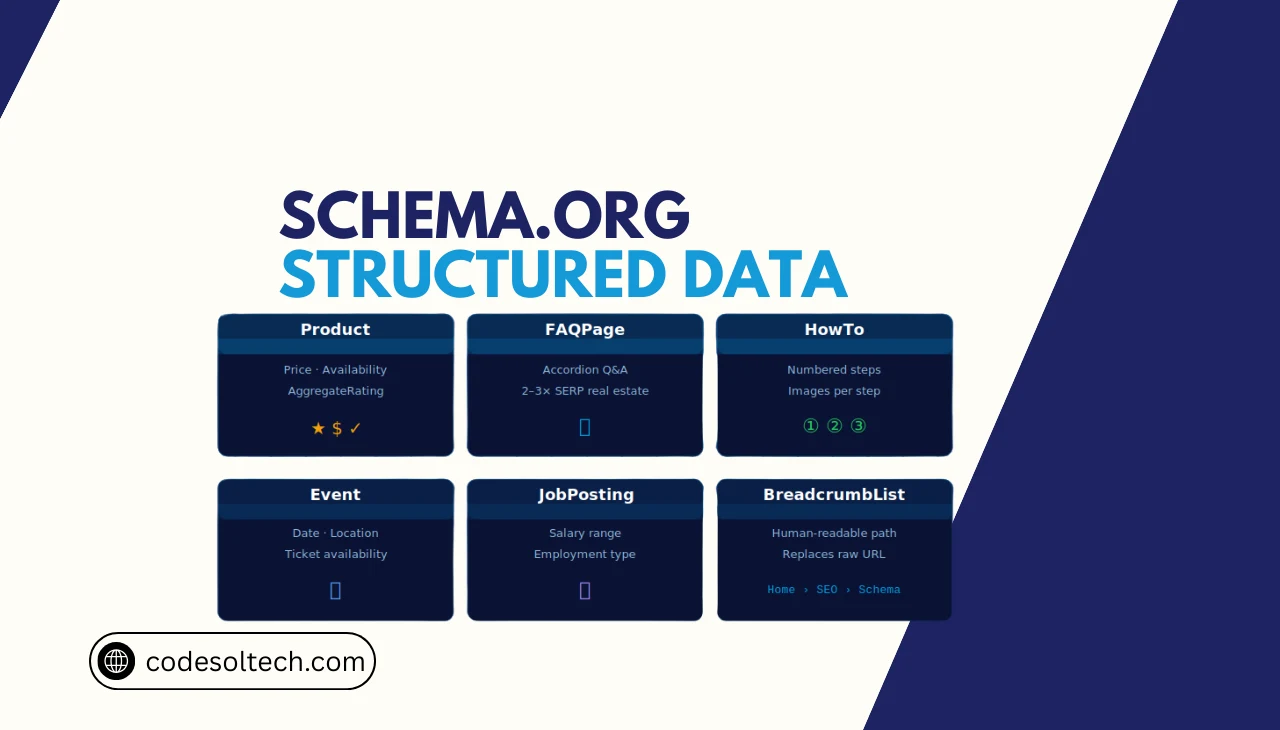
Types of Rich Results Schema Markup Enable
Google renders 35+ distinct rich result formats, each tied to a specific Schema.org Type. The most commercially significant rich result types are:

- Product — Displays price, availability, and
AggregateRatingdirectly in the SERP. - FAQPage — Expands the listing with accordion Q&A pairs; increases SERP real estate by 2–3×.
- HowTo — Renders numbered steps with optional images in rich results on desktop.
- Recipe — Shows cook time, calories, and ratings in a visual card format.
- Event — Displays date, location, and ticket availability for upcoming events.
- JobPosting — Enables listings in Google Jobs with salary range and employment type.
- BreadcrumbList — Replaces the URL path with human-readable navigation labels in the snippet.
- VideoObject — Adds video thumbnail, duration, and upload date to video content listings.
How Does Structured Data Help Search Engines Understand Entities?
Entities are people, places, organizations, products, and concepts that exist independently of any single document. Google’s Knowledge Graph stores over 500 billion facts about approximately 5 billion entities, according to Google’s official documentation.
Structured data accelerates entity disambiguation — the process of determining which real-world entity a page refers to by declaring sameAs links to authoritative external URIs.

The sameAs property connects a local entity declaration to its canonical identifier in an external knowledge base. An example implementation for an organization:
{
"@type": "Organization",
"name": "CodeSolTech",
"url": "https://codesoltech.com",
"sameAs": [
"https://www.wikidata.org/wiki/[Entity-ID]",
"https://twitter.com/codesoltech",
"https://www.linkedin.com/company/codesoltech"
]
}By linking to Wikidata, Google resolves which CodeSolTech the markup refers to and merges the declared attributes with existing Knowledge Graph facts. This entity consolidation strengthens an organization’s Knowledge Panel, improves brand query accuracy, and builds the topical authority signal that semantic SEO requires. Read more about technical SEO entity optimization strategies used in modern ranking frameworks.
What Structured Data Errors Prevent Rich Results?
Google rejects structured data and withholds rich results when markup contains 4 categories of errors:

- Missing Required Properties — Every rich result Type has mandatory fields.
Productrequiresname;ReviewrequiresitemReviewedandreviewRating. Omitting them disqualifies the page. - Spammy or Misleading Markup — Marking up content that is invisible to users, or claiming properties the page does not substantiate, triggers a manual action under Google’s spam policies.
- Incorrect Property Data Types — Supplying a string where an integer is required, or a URL where a
Dateobject is expected, produces parsing errors that invalidate the block. - Markup–Content Mismatch — Structured data must reflect the visible page content. A
Productmarkup block on a blog article page creates a policy violation.
Validate all structured data using 2 official tools before deployment:
- Google Rich Results Test — Confirms eligibility for specific rich result types.
- Schema Markup Validator — Detects syntax errors and undefined properties against the full Schema.org specification.
How to Implement JSON-LD Schema Markup: A Technical Workflow
Structured data implementation follows a 5-step technical workflow:

- Identify the Primary Entity Type — Audit the page’s content intent and select the most specific Schema.org Type. A page listing software agency services maps to
ProfessionalServicenested withinLocalBusiness. - Map Required and Recommended Properties — Cross-reference Google’s structured data documentation to identify which properties are required for rich result eligibility and which are recommended for maximum entity signal.
- Author the JSON-LD Block — Write the
<script type="application/ld+json">block, nest sub-entities, and includesameAslinks to external authority sources. - Inject Into the Page — Place the block in the
<head>section for static sites. For WordPress sites, use a plugin (e.g., Yoast SEO, RankMath, or Schema Pro) or inject viawp_head(). For JavaScript frameworks, inject server-side to ensure Googlebot receives the markup in the initial HTML response. Learn how WordPress development handles schema injection at scale. - Validate and Monitor — Run the Rich Results Test immediately post-deployment. Monitor Google Search Console’s Enhancements report weekly for detected markup and any new errors.
Structured Data vs. Meta Tags: Core Technical Differences
Meta tags and structured data serve different functions in the on-page SEO architecture. Meta tags communicate page-level metadata to search engines: the title tag names the document; the meta description summarizes it; the canonical tag declares the preferred URL. These are document-level signals.

Structured data communicates entity-level facts that exist within the document. A single page carries one set of meta tags but can contain multiple JSON-LD blocks for different entities — a BreadcrumbList, an Article, a Person (author), and an Organization (publisher) each contributing distinct signals to the knowledge graph simultaneously.
The 3 key functional differences are:
- Scope — Meta tags describe the document; structured data describes entities within the document.
- Output — Meta tags influence snippet text; structured data enables rich result formats.
- Machine Readability — Meta tags use string values; structured data uses a typed, linked-data graph that search engines traverse.
Advanced Schema Patterns: Building Entity Graphs for Topical Authority
Topical authority in the Holistic SEO framework emerges from the density and coherence of entity relationships across an entire website, not from a single page. A website that covers Web Architecture as its macro topic must declare consistent entity relationships across all supporting pages using structured data.

This site-wide entity graph tells Google that the domain is the authoritative source for a connected knowledge domain.
3 advanced JSON-LD patterns accelerate topical authority construction:
- Nested Entity References — Use
@idto declare a URI for each entity and reference it across multiple pages instead of rewriting the full object. This links pages into a coherent graph. - Speakable Schema — The
speakableproperty (SpeakableSpecification) marks sections of text that are concise, factual summaries suitable for voice assistants and AI overviews to read aloud. - ItemList for Content Hubs —
ItemList+ListItemmarkup on category or hub pages signals the hierarchical relationship between the hub and its child articles — the exact structure required for a content silo architecture.
Google’s Knowledge Graph was introduced in 2012 with the stated goal of understanding “things, not strings.” Structured data is the primary mechanism a website uses to declare what things it contains — making it the foundational layer of any semantic SEO strategy.
Key Takeaways: Structured Data Facts Every SEO Must Know

- Schema.org defines 800+ Types and 1,400+ Properties for entity classification.
- JSON-LD is Google’s recommended structured data format; it decouples markup from HTML.
- Rich snippets increase average CTR by 20–30% for qualifying pages.
- The
sameAsproperty connects local entity declarations to external Knowledge Graph identifiers. - Google’s Knowledge Graph stores facts about 5 billion entities across 500 billion declared facts.
- Structured data errors in 4 categories — missing properties, misleading markup, wrong data types, and content mismatches — block rich result eligibility.
- A site-wide entity graph built through consistent JSON-LD signals topical authority to Google’s ranking systems.
Final Words
Structured data transforms a webpage from a text document into a declared knowledge asset.
Schema.org, JSON-LD, and rich snippets form a 3-layer system: vocabulary, syntax, and visual reward.
Every JSON-LD block a website publishes contributes one more fact to Google’s entity model of that domain, and entity density is how topical authority is built, measured, and ranked.
Need Schema Markup Implemented on Your Website?
The CodeSolTech SEO team implements Schema.org structured data across all page types — from LocalBusiness to Product to FAQPage — validated against Google’s Rich Results guidelines before deployment.


